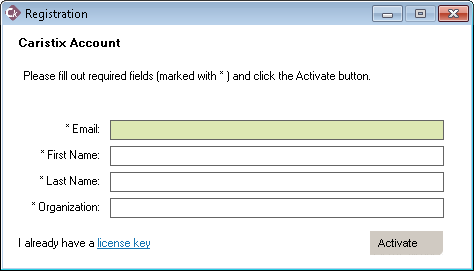
If you have a trial version, you will need to purchase an annual license to continue using Cloak after the end of the trial period.
De-identification in Cloak works as follows:
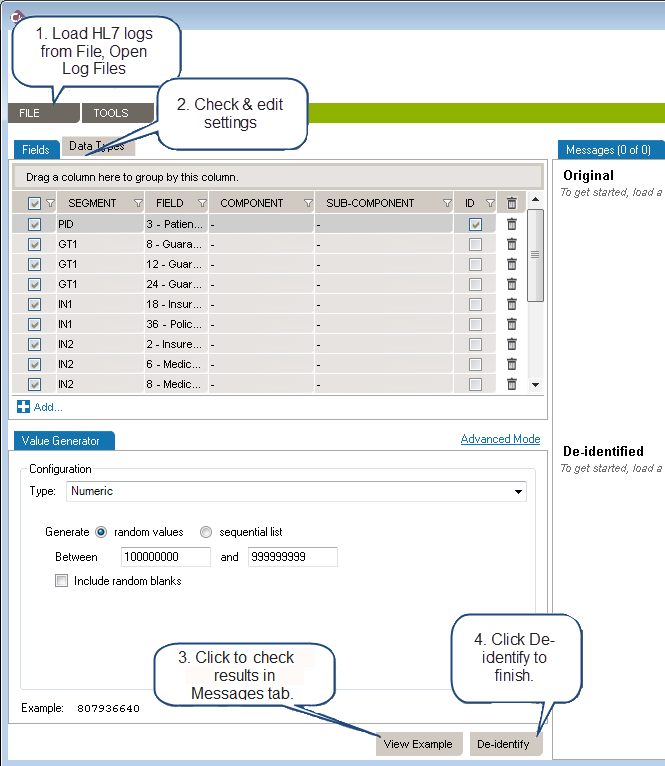
Load the HL7 message that requires de-identification:
The log is loaded in Messages tab. The tab also indicates the number of messages in the viewing pane and the total number of messages in the file you loaded. The Original pane displays the log you loaded while the De-identified pane displays the de-identified log. The split screens scroll synchronously so that the data displayed is mirrored in the original and de-identified logs.
Resize vertically to change the quantity of data displayed in the viewing pane. Place the pointer on the line dividing the two panes and drag the window to increase or decrease its size. Click Hide and Show buttons to hide or view panes as needed.
The fields and data types set for de-identification are highlighted in red for easy visibility.
On the left side of the screen are the de-identification settings listed under the Fields and Data Types tabs. Cloak loads settings to cover the 18 HIPAA identifiers by default.
To add a de-identification rule under Fields or Data Types:
To remove a setting, click the trashcan at the end of the line.
Once you have created and configured all the selectors applicable to the HL7 log to be de-identified, click View Example at the bottom of the left hand pane. A preview of the de-identified log file will appear. Scroll through the log in the viewing panes to verify the potential results of the de-identification process.
Once reviewed and after applying any changes:
Once saved, a De-identification Process Report dialogue box will open asking if you wish to create a de-identification process report. Click Yes or No. If Yes is clicked, you will be prompted to choose a location to save the generated PDF and to give a name to the file. Click Save and the file will be saved to the specified location. The PDF of the De-identification Process Summary will open on your desktop for review.
Once a set of selectors have been chosen for the de-identification of a log file, that set can be saved for reuse.
Once a log file has been opened, the saved de-identification rules can be applied by clicking Open de-id rules from the drop down menu bar under File in the the top menu bar.
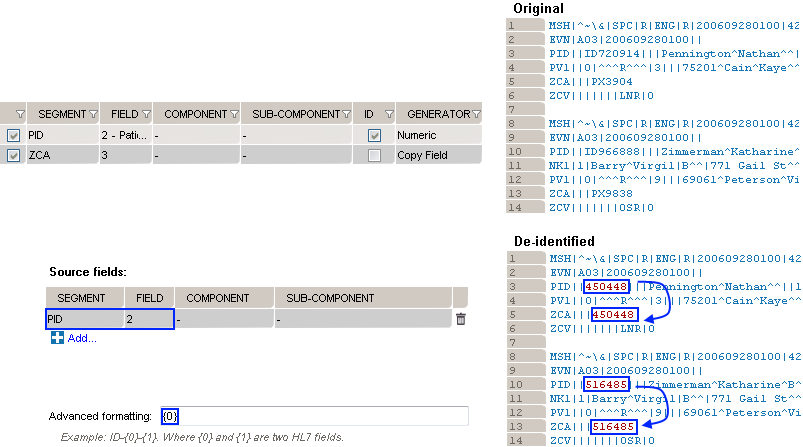
This generator replicates the value from another de-identified field.
How to use the “Copy Another Field” generator:
Example 1: copy the replacement MRN value from PID. 2 to ZCA.3
Cloak has a number of options that can be set. From the main menu bar, click Tools, then Options. In the Options dialog box that opens, there are three categories: Reference Profile, Windows Service Settings, Delimiters, Settings and Preferences.
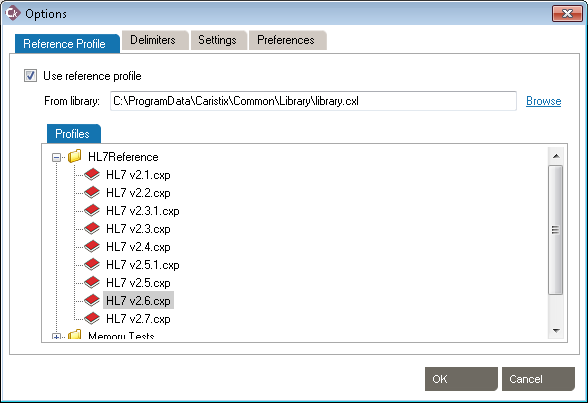
These settings allow the use of HL7 reference profiles to parse logs. Open the Reference Profile tab.
These settings allow the addition of specific delimiters to the log file to assist with manageability and readability. They include:
Click OK to save the delimiters.
Click OK to save the settings.
Click OK to save the Preferences.